Stress Testing / Performance Testing
We design and execute stress and performance tests for mission-critical systems. We simulate real-world load, instrument monitoring, and help your IT team identify bottlenecks and validate fixes with comparable evidence.
In online auctions, e-commerce, accounting systems or other critical platforms, a performance degradation directly impacts revenue and brand reputation.
In addition, many industries have critical dates and events that push systems to their limits. Home goods and consumer electronics retailers often experience major traffic peaks around dates like Mother’s Day, special campaigns or seasonal promotions. E-commerce platforms face events such as Cyber Monday, Black Friday and large-scale releases.
In these contexts, the system cannot fail. Ideally, at least 15 days before a critical date, the organization should have concrete evidence that both infrastructure and application will handle the expected load without degradation or disruption.
Each industry has its own high-demand calendar: accounting close, commercial campaigns, live auction events, tax deadlines, promotions coordinated with media or influencers. Stress testing helps you anticipate risk and reach those moments with predictability.
A stress test is not just a technical exercise: it’s a risk-management tool to protect revenue, reputation and operational continuity when the stakes are highest.
We choose the most appropriate tool based on your system type, architecture and objectives.
We execute stress tests in a controlled, measurable and repeatable way, working closely with IT to identify the issue and verify the fix with comparable evidence.
Typical execution dashboards: message volume, concurrent users, end-to-end latency, stream stability and confirmation loss.
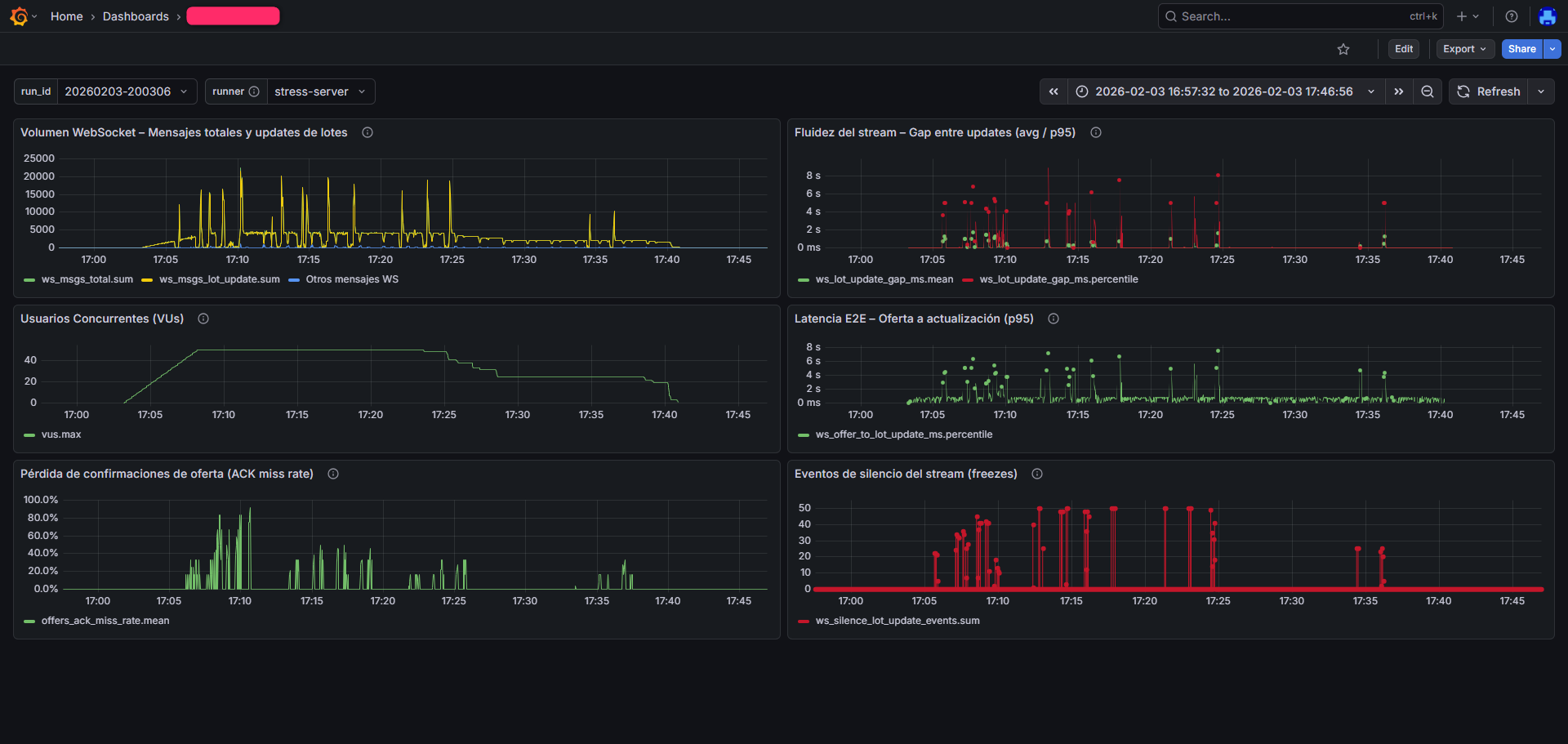
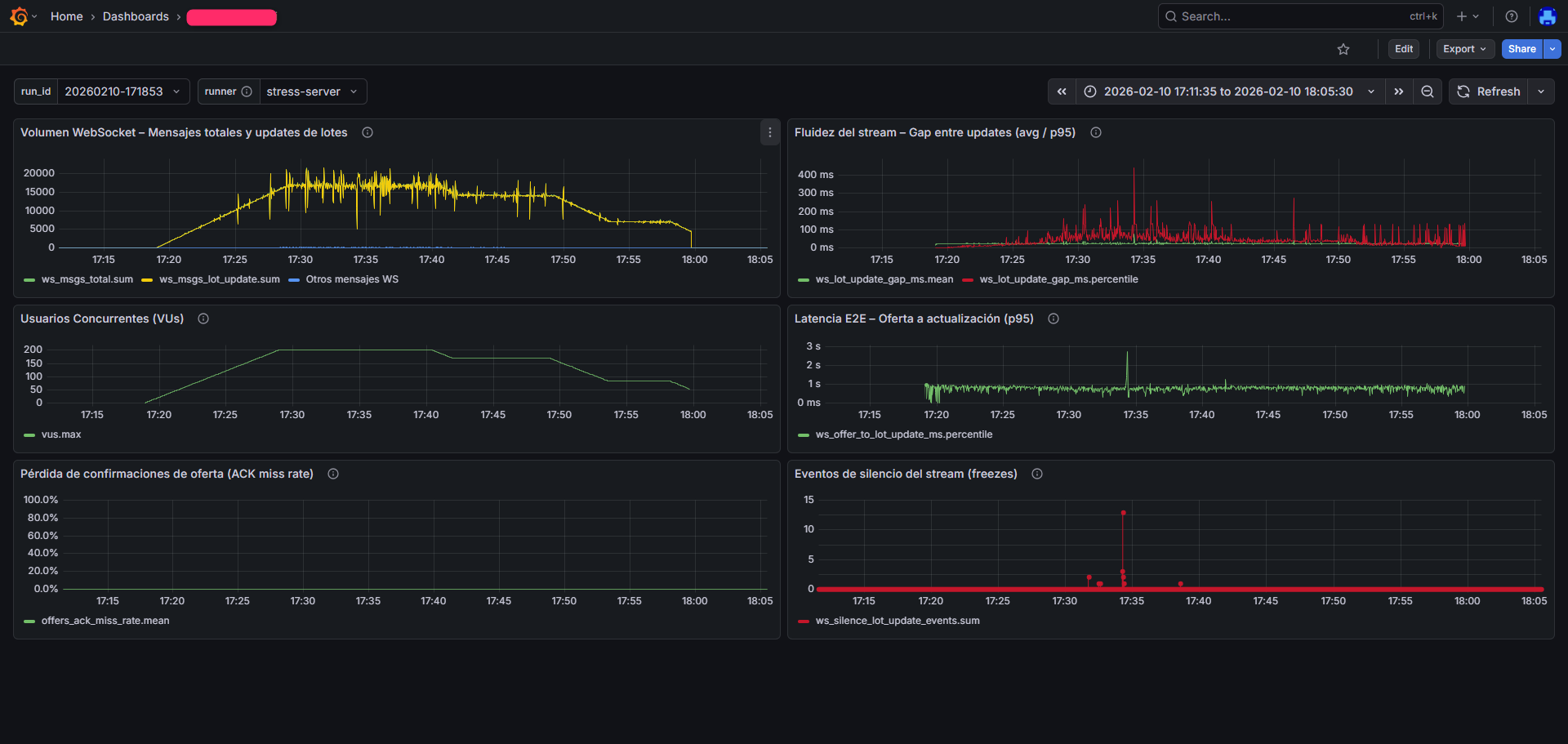
Note: representative metrics are shown without exposing sensitive client information.
We have executed stress tests in industries where performance directly impacts revenue and operations.
Mother’s Day, Cyber Monday, Black Friday, accounting close,
a live auction, a promotional campaign or a product launch.
If the system fails at that moment, the impact is not technical.
It’s financial.
Tell us briefly about your scenario and we’ll schedule a technical conversation. If you already have a planned event or expected peak, include it — it helps design the test accurately.